Nearest Neighbor Descent (NND) (Dong et al. 2011) is affected by hubness (Bratić et al. 2019): this is when some items in a dataset appear as a near neighbor of other points very frequently. This can result in reduced accuracy of the approximate nearest neighbor graph produced by NND and may be an intrinsic problem in high dimensional datasets (although see (Low et al. 2013) for a dissenting view).
In this vignette we will use synthetic data to explore the issue, and
use the k-occurrences of a neighbor graph to identify when NND is at
risk of producing less accurate results. We will also look at some ways
to ameliorate the effects of hubness. This will make use of some utility
functions in rnndescent which can be useful for assessing
the accuracy of the approximate nearest neighbors: k_occur,
neighbor_overlap, and merge_knn.
First, to control the pseudo-random number generation:
set.seed(42)Now let’s create some Gaussian data to test with. First, a low-dimensional example:
In this vignette, we are interested in the 15 nearest neighbors. To
get the exact nearest neighbors, we use the brute_force_knn
function with k = 15:
g2d_nnbf <- brute_force_knn(g2d, k = 15, metric = "euclidean")This will act as our “ground truth” and we will compare how well NND
does. To use NND to find the approximate nearest neighbors, we use the
nnd_knn function:
g2d_nnd <- nnd_knn(g2d, k = 15, metric = "euclidean")To calculate the accuracy of NND we will use the
neighbor_overlap function to find the mean overlap of the
nearest neighbor indices produced by the methods.
0 means that none of the exact 15-nearest neighbors were
in the list of 15-nearest neighbors that NND found, and 1
means they all were.
With low-dimensional data, nearest neighbor descent does very well:
neighbor_overlap(g2d_nnbf, g2d_nnd, k = 15)
#> [1] 1Now let’s see what happens with a high-dimensional (1000 features):
Again we will use brute force to generate the true nearest neighbors.
g1000d_nnbf <- brute_force_knn(g1000d, k = 15, metric = "euclidean")Let’s do NND on the high dimensional data…
g1000d_nnd <- nnd_knn(g1000d, k = 15, metric = "euclidean")…and see how well it does:
neighbor_overlap(g1000d_nnbf, g1000d_nnd, k = 15)
#> [1] 0.7844667Still OK, but not as good as we might like.
Comparing Low- and High-Dimensional Nearest Neighbors
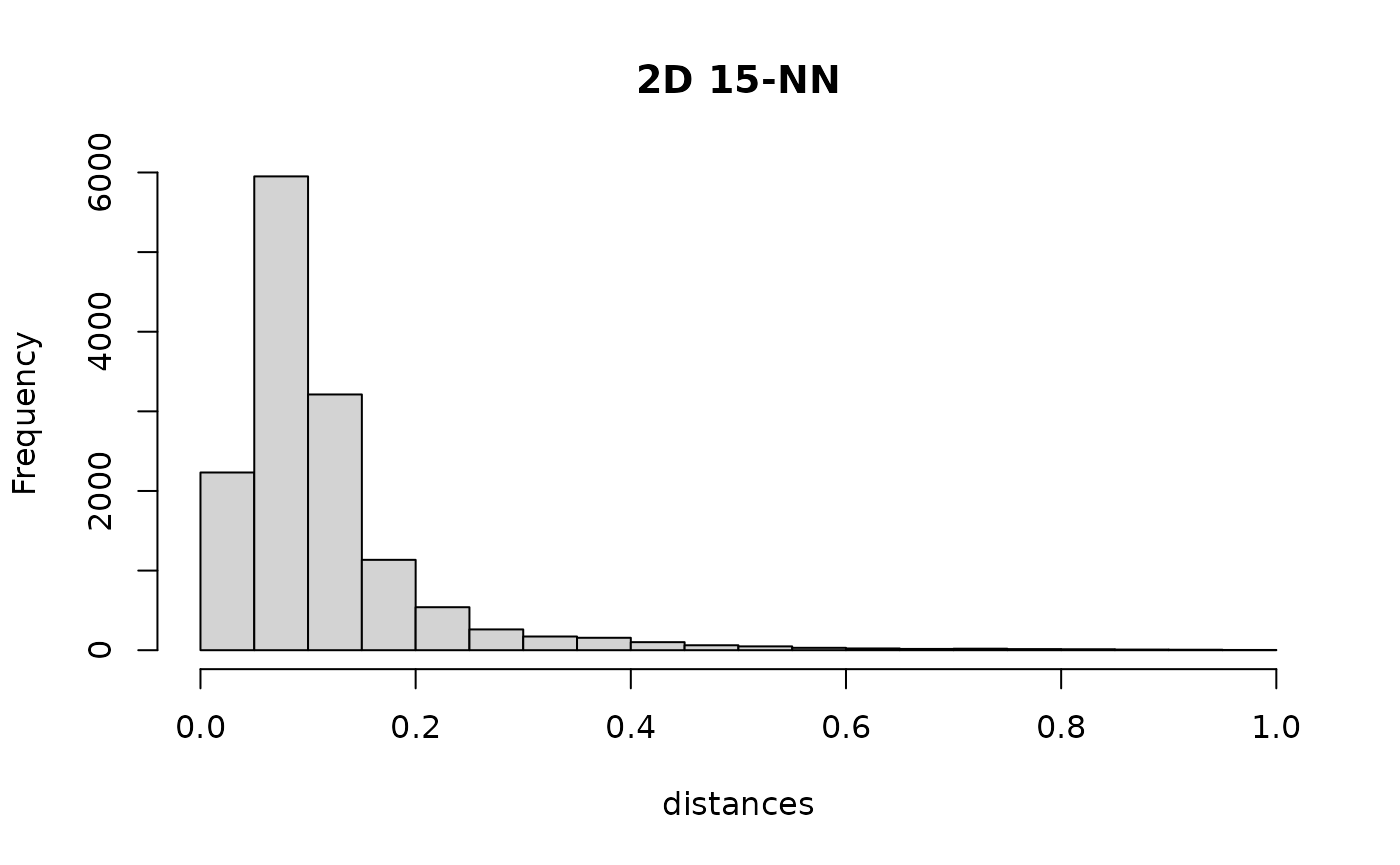
Let’s look at the distribution of nearest neighbor distances in high and low dimensions (for easier comparison, I have normalized them with respect to the largest distance)
hist(g1000d_nnbf$dist[, -1] / max(g1000d_nnbf$dist[, -1]), xlab = "distances", main = "1000D 15-NN")
Compared to low dimensional data, we can see that the high dimensional distances are distributed around a higher distance as well as more symmetric in their distribution.
Here are the distribution of the neighbor distances in the high-dimensional case for the neighbors found by NND:
hist(g1000d_nnd$dist[, -1] / max(g1000d_nnd$dist[, -1]),
xlab = "distances",
main = "1000D 15-NND"
)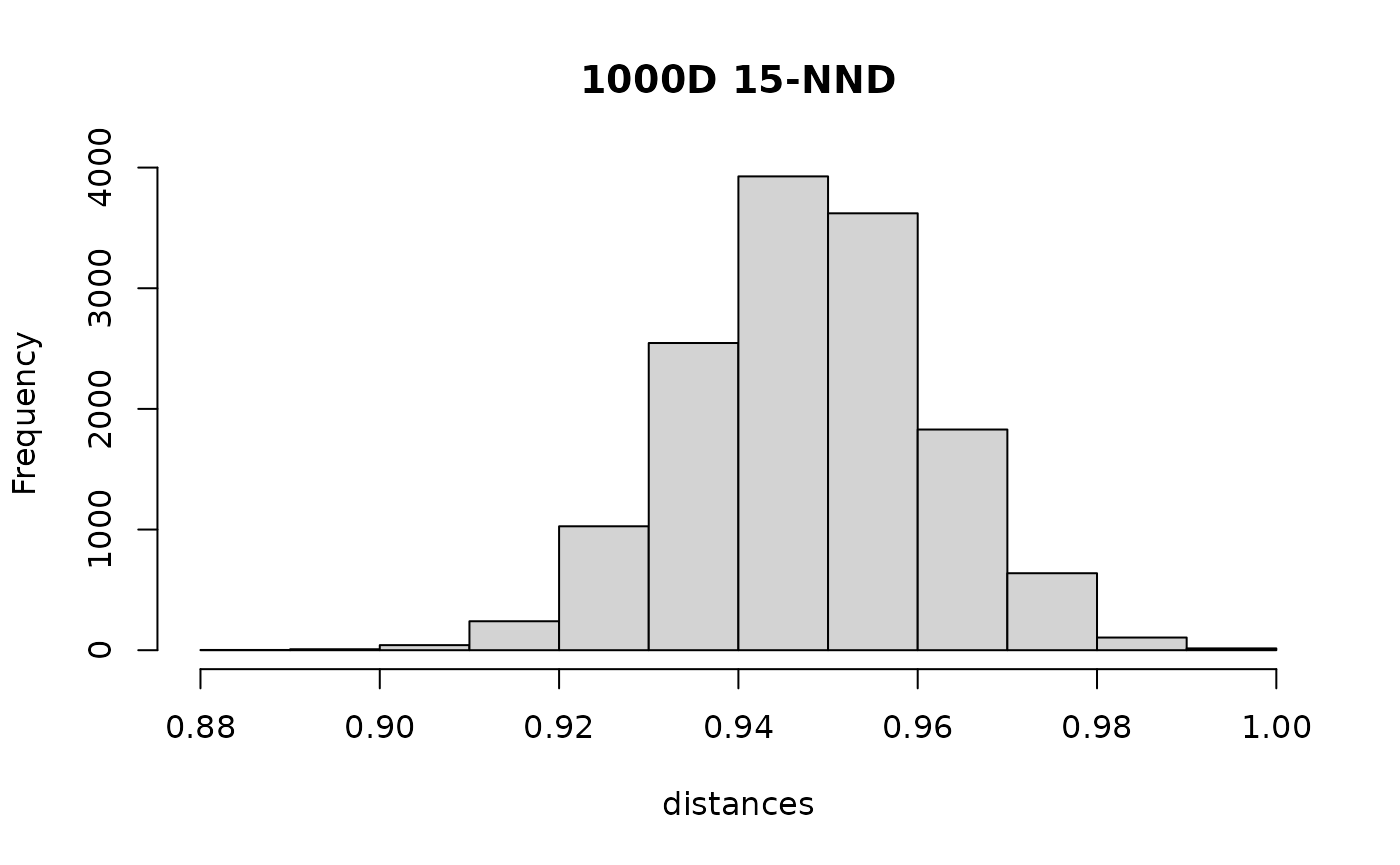
Pretty much indistinguishable from the exact results, so it seems like there isn’t an obvious diagnostic from the distances themselves.
Is the distribution of the errors in the NND results uniform or are some items neighborhoods noticeably better predicted than others? This function will calculate a vector of the relative RMS error between two sets of neighbors in terms of distances:
nn_rrmsev <- function(nn, ref) {
n <- ncol(ref$dist) - 1
sqrt(apply((nn$dist[, -1] - ref$dist[, -1])^2 / n, 1, sum) /
apply(ref$dist[, -1]^2, 1, sum))
}We don’t include the first nearest neighbor distances, as these are
invariably the self distances which leads to an uninteresting number of
zero error results. This measure of error is a bit less strict than
neighbor_overlap as a neighbor that is outside the true
kNN, but which has a comparable distance, will be penalized a less
harshly than a more distant point.
Here’s a histogram of RRMS distance errors:
g1000d_rrmse <- nn_rrmsev(g1000d_nnd, g1000d_nnbf)
hist(g1000d_rrmse,
main = "1000D distance error",
xlab = "Relative RMS error"
)
None of the relative errors are actually that large, so if you only care about the value of kth nearest neighbor distances, then even in the 1000D case, we still get decent results in this case. We can also see that there is a clear distribution of errors, where an appreciable number of items have zero RRMS distance errors, but there a few items which have the largest error.
We can also get out the overlap on a per-item basis. If you set
ret_vec = TRUE, neighbor_overlap will now
return a list with the individual overlaps as the overlaps
vector (the overall mean average overlap is returned as the
mean item). Here is a histograms of the accuracies:
g1000d_nnd_acc <-
neighbor_overlap(g1000d_nnbf, g1000d_nnd, k = 15, ret_vec = TRUE)$overlaps
hist(g1000d_nnd_acc,
main = "1000D accuracy",
xlab = "accuracy",
xlim = c(0, 1)
)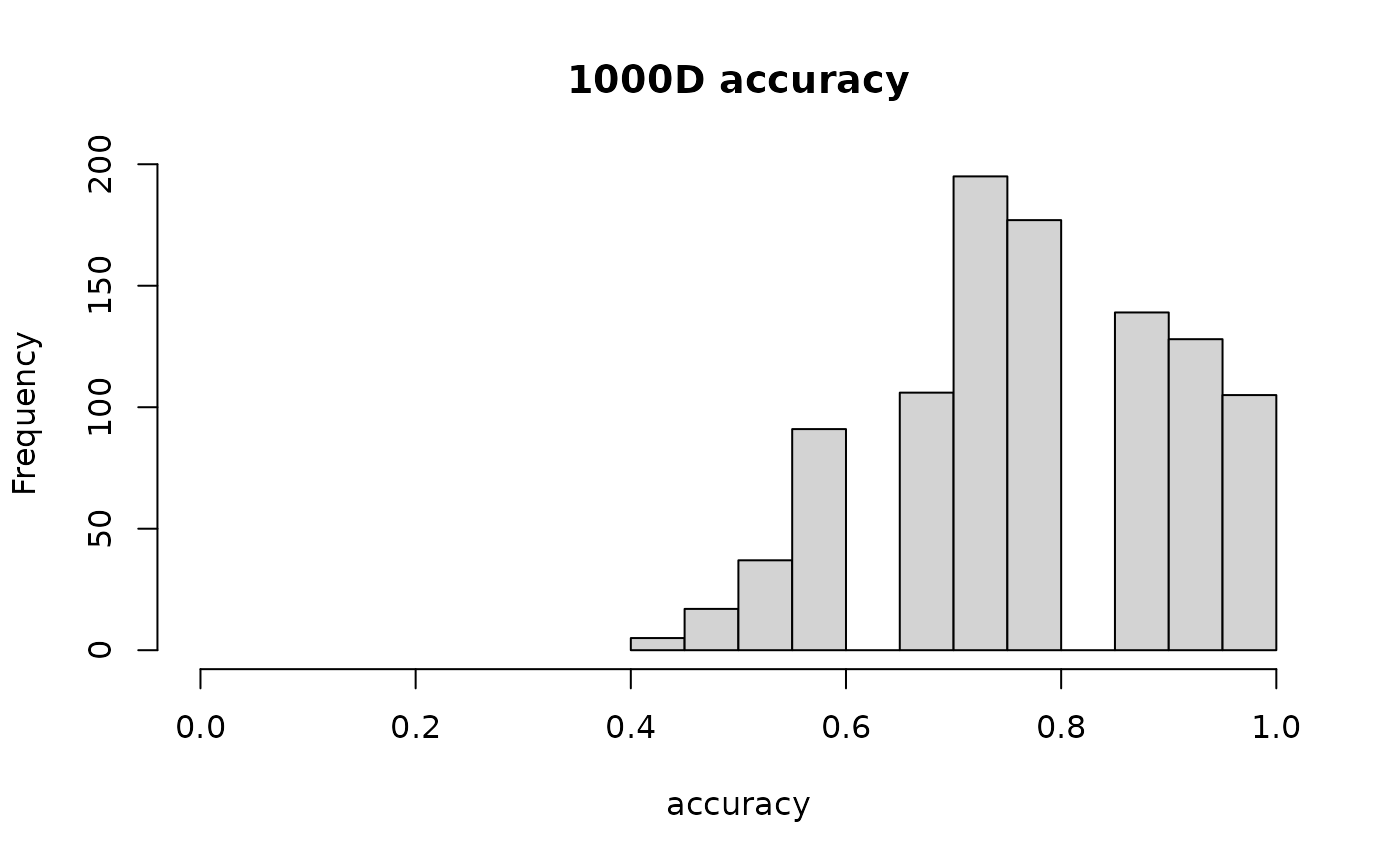
This shows a similar pattern: some items have very high accuracy and some have noticeably worse accuracy than average. For completeness, here is the relationship between accuracy and RRMSE:
plot(
g1000d_nnd_acc,
g1000d_rrmse,
main = "RRMSE vs accuracy",
xlab = "accuracy",
ylab = "RRMSE"
)
Nothing very surprising here: there’s a fairly consistent spread of RRMSE for a given accuracy.
So whether you use an error in the distance or accuracy to measure how well the approximate nearest neighbors method is working, at least in this case, a high dimensional dataset affects some items more than others.
Detecting Hubness
(Radovanovic et al. 2010) discusses a
technique for detecting hubness: look for items that appear very
frequently in the k-nearest neighbor graph. The k_occur
function counts “k-occurrences” of each item in a dataset, i.e. a count
of the number of times an item appears in the k-nearest neighbor graph.
You can also see it as reversing the direction of the edges in the
k-nearest neighbor graph and then counting the in-degree of each
item.
If the distribution of neighbors was entirely uniform we would expect to see each item appear times. If there are hubs then the k-occurrence could get as large as the size of the dataset, . An item which appears in the neighbor graph fewer than times could be termed an “antihub”. Our definition of a neighbor of an item always includes the item itself, so we would expect the minimum -occurrence to be .
Also, because there are always only edges in a -nearest neighbor graph, if an item appears more than the expected amount this implies that other items must be under-represented. Practically speaking, there are always going to be items with a larger -occurrence than expected and hence some with a lower -occurrence, so hubness or anti-hubness is more a case of deciding on a cut-off after which the presence of an item with a lot of neighbors starts causing you problems, which is going to be dependent on what you are planning to do with the neighbor graph (and probably the number of neighbors you want).
k-occurrence in the 2D case
First, let’s look at the 2D case using the exact k-nearest neighbors:
g2d_bfko <- k_occur(g2d_nnbf, k = 15)
summary(g2d_bfko)
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 1 13 15 15 17 24The mean average of the
-occurrence
is never helpful: as noted above there are always
edges in the neighbor graph, so the mean
-occurrence
is always
.
However the other descriptions of the distribution are informative. The
median
-occurrence
is also 15, which is a good sign, and the values at 25% and
75% aren’t too different other. The maximum
-occurrence
is less than
.
The minimum value is 1 which means there are anti-hubs in
the dataset, but:
sum(g2d_bfko == 1)
#> [1] 1there is only one anti-hub in this dataset. Here’s a histogram of the k-occurrences:
hist(g2d_bfko, main = "2D 15-NN", xlab = "k-occurrences")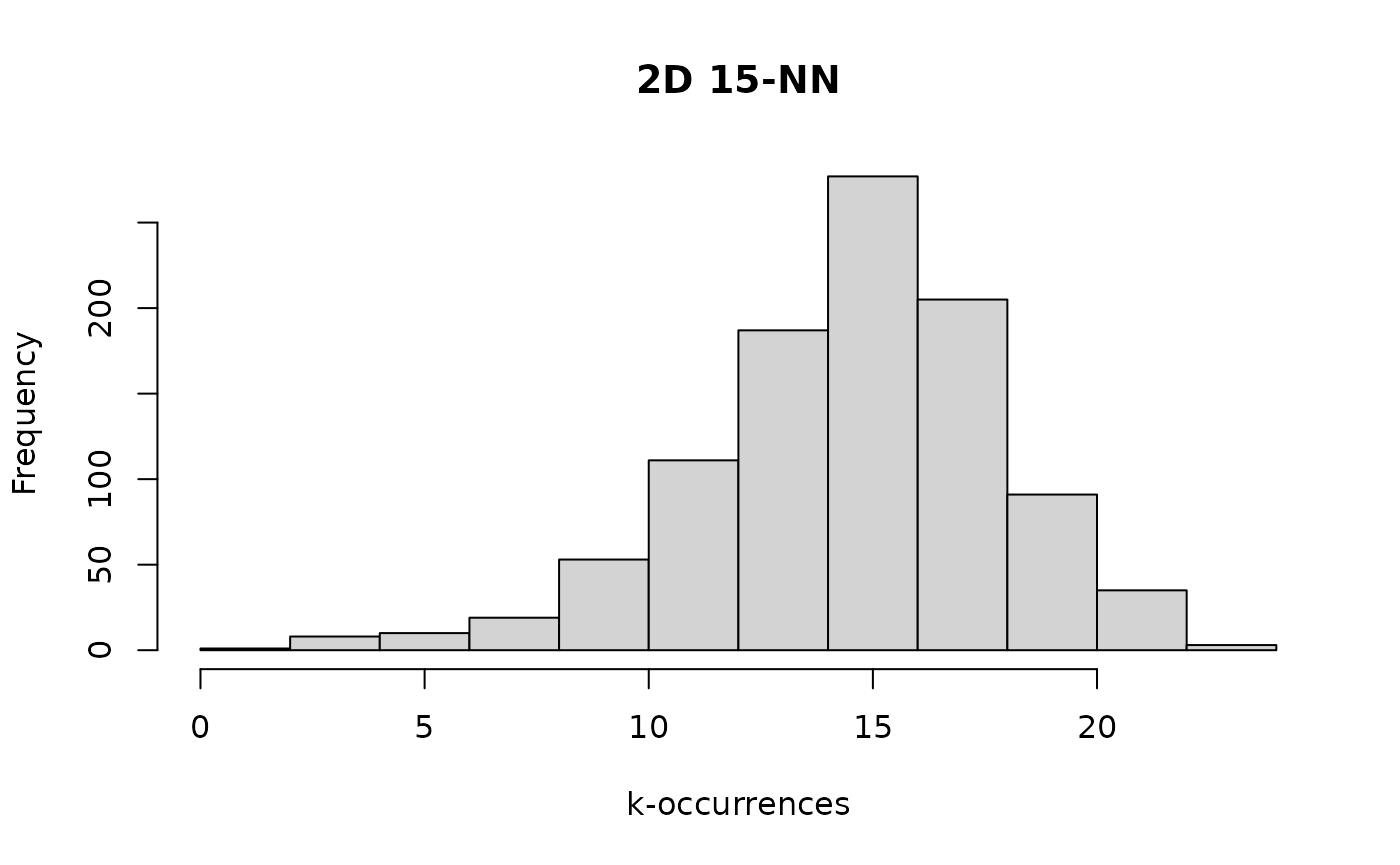
This unremarkable-looking distribution is a visual indication of a dataset without a lot of hubness and anti-hubs lurking to cause problems for nearest neighbor descent.
k-occurrence in the 1000D case
Here’s what the k-occurrence histogram looks like for the high dimensional case:
g1000d_bfko <- k_occur(g1000d_nnbf$idx, k = 15)
hist(g1000d_bfko, main = "1000D 15-NN", xlab = "k-occurrences")
The differences are pretty stark. The first thing to notice is the x-axis. In the 2D case, the maximum k-occurrence was ~20. For the 1000D we are looking at ~300. It’s hard to see any details, so let’s zoom in on the same region as the 2D case by clipping any k-occurrence larger than the largest 2D k-occurrence:
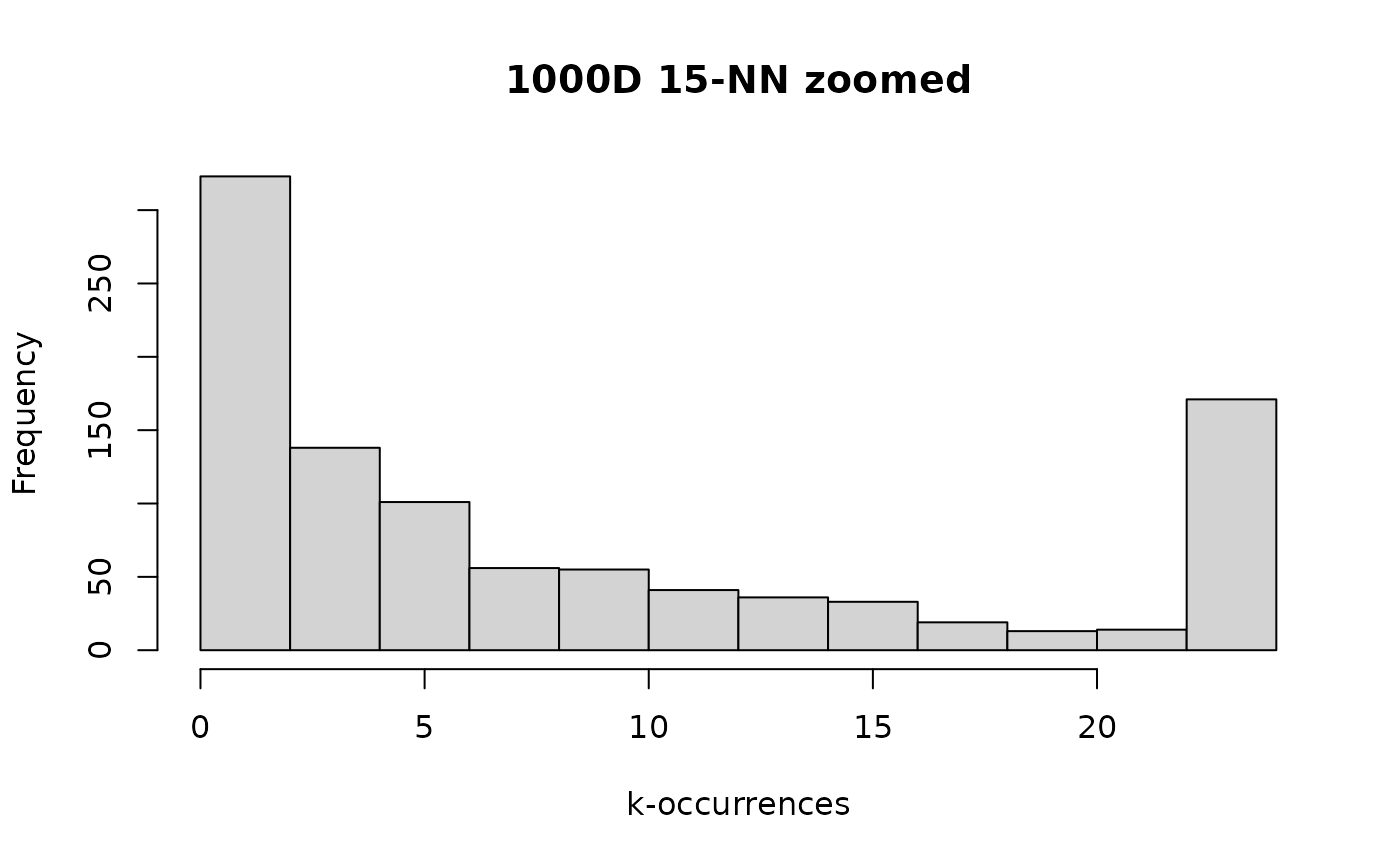
It’s a very different distribution to the 2D case: we have a large number of anti-hubs and a noticeable number of hubs. There’s certainly no peak at a k-occurrence of 15. Comparing the numerical summary with the 2D case is instructive:
summary(g1000d_bfko)
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 1.00 2.00 5.00 15.00 14.25 345.00Again, here’s a good reminder that the mean k-occurrence is of no value. The median k-occurrence immediately communicates the difference between the 2D case. We can also see that the maximum k-occurrence means that there is one point which is considered a close neighbor of over one third of the dataset.
How many anti-hubs are there?
sum(g1000d_bfko == 1)
#> [1] 221A quarter of the dataset does not appear as a neighbor of any other point. This has serious implications for using a neighbor graph for certain purposes: you cannot reach a quarter of the dataset by starting at an arbitrary point in the graph and following neighbors.
This also might point to why nearest neighbor descent has trouble with this high dimensional case: if we rely on points turning up as a neighbors of other points in order to introduce them to potential neighbors, the fact that so many of the points in this dataset aren’t anyone’s actual neighbors would suggest they are unlikely to get involved in the local join procedure as much as other points.
k-occurrence as a diagnostic of NND failure
We have now shown that we can use k-occurrences on the exact nearest neighbors of low and high dimensional data to detect the existence of hubs, which in turn might lead us to suspect that the approximate nearest neighbors found by nearest neighbor descent may not be very accurate. But that’s not a very useful diagnostic because if we have the exact neighbors we don’t need to run NND in the first place. But even if the approximate nearest neighbor graph produced by NND isn’t highly accurate, does it still show similar characteristics of hubness?
g1000d_nndko <- k_occur(g1000d_nnd$idx, k = 15)
hist(g1000d_nndko, main = "1000D 15-NND", xlab = "k-occurrences")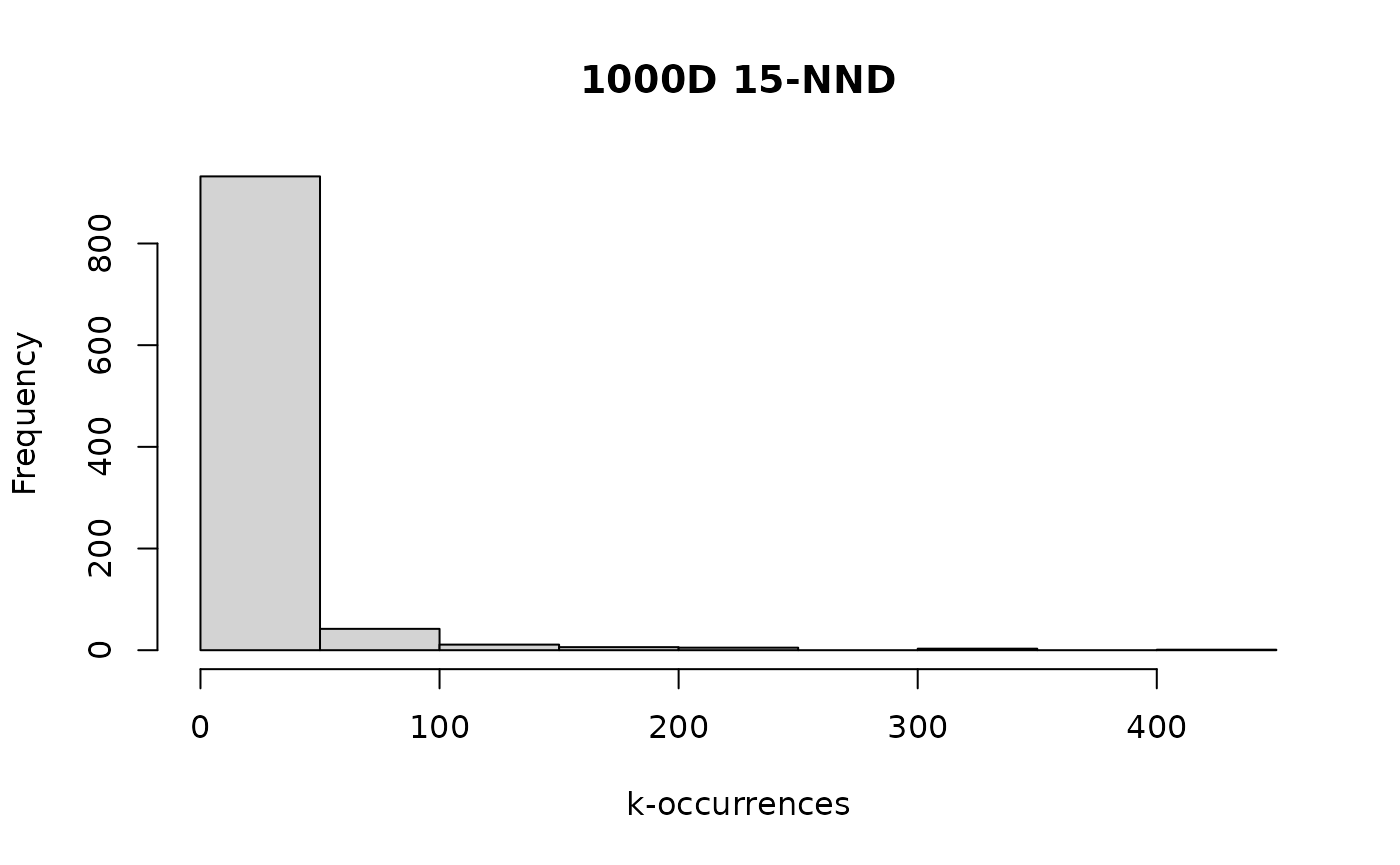
That seems similar to the true results, and zooming in like we did with the exact results:
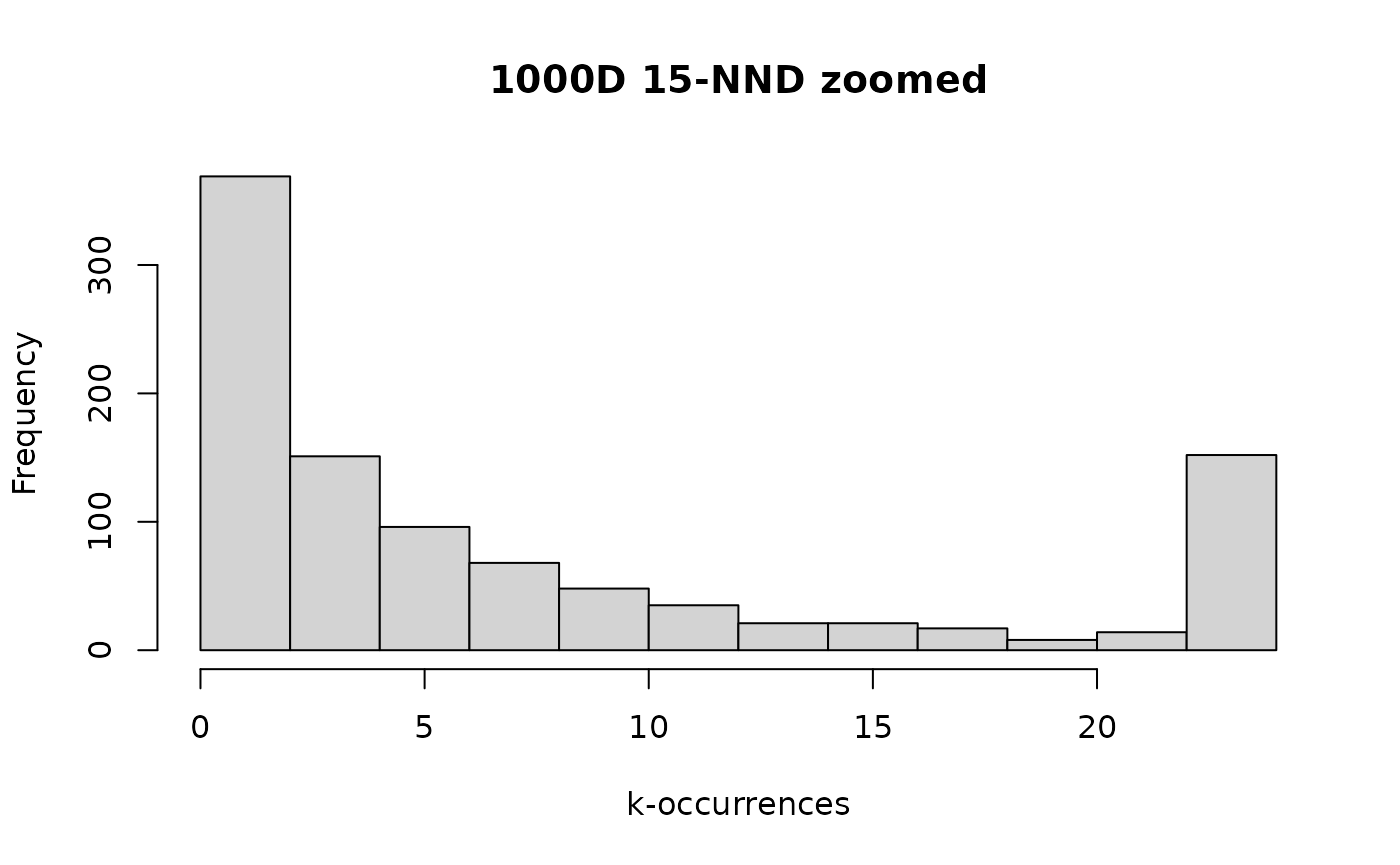
Visually this looks a lot like the distribution of the exact results. Next, the numerical summary:
summary(g1000d_nndko)
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 1 1 4 15 12 406
sum(g1000d_nndko == 1)
#> [1] 254Quantitatively, this also tracks the exact results: the median k-occurrence is much smaller than , there is a hub with a very large number of neighbors (larger than in the exact case but to a similar degree) and a similar number of anti-hubs.
So this suggests a way to diagnose if the nearest neighbor descent routine may have low accuracy: look at the distribution of the k-occurrences of the resulting approximate nearest neighbor graph (or even just the maximum value). A value that is may mean a reduced accuracy. Of course, this isn’t foolproof, because even if NND did a perfect job then we would still get these sorts of values, but it’s a starting point.
Taking the distribution of k-occurrences as a whole, the approximate results seem to track the exact results fairly well, but as we have seen, the errors in the approximate results are not uniformly distributed across the data. So let’s see how well the NND k-occurrences “predict” the exact results:
plot(g1000d_nndko, g1000d_bfko,
xlab = "approximate", ylab = "exact",
xlim = c(0, max(g1000d_nndko, g1000d_bfko)),
ylim = c(0, max(g1000d_nndko, g1000d_bfko)),
main = "1000D k-occ"
)
abline(a = 0, b = 1)
cor(g1000d_nndko, g1000d_bfko, method = "pearson")
#> [1] 0.9939508The overall relationship seems strong. The line on the plot is x=y, so we can see that at high values of the k-occurrence the NND results tend to over-estimate the k-occurrence, but these are such large values that this hardly matters, and there is no ambiguity over which nodes are most hub-like.
Zooming in to lower values of the k-occurrence:
plot(g1000d_nndko, g1000d_bfko,
xlab = "approximate", ylab = "exact",
xlim = c(0, max(g2d_bfko)),
ylim = c(0, max(g2d_bfko)),
main = "1000D low k-occ"
)
abline(a = 0, b = 1)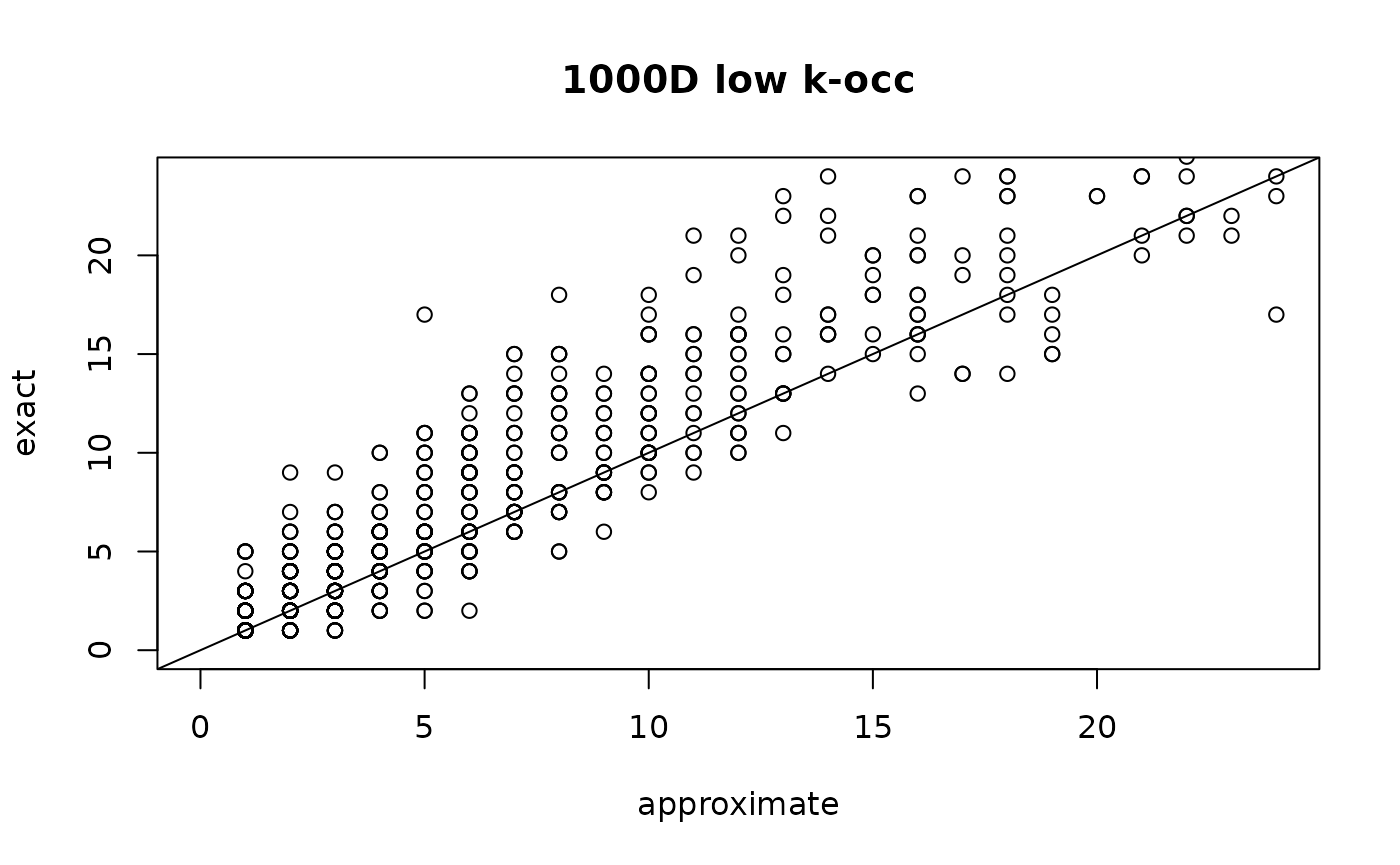
here it seems that there is a tendency to over-estimate the k-occurrence. Anti-hubs are also not perfectly identified, but there are no true anti-hubs which appear more than a small number of times in the approximate neighbor graph.
Detecting Poorly Predicted Neighbors
We’ve seen that some objects have their neighbors predicted better than others. Based on everything we’ve seen so far about k-occurrences and NND, it would be reasonable to wonder: are the items in a dataset with poorly predicted neighbors the anti-hubs (predicted or exact)? This would at least give us some way of detecting those items that were likely to have low accuracy neighborhoods: perhaps they could be treated specially (or by some other algorithm).
Here’s a plot of the accuracy against the k-occurrences of the NND neighbors:
plot(g1000d_nndko, g1000d_nnd_acc,
xlab = "NND k-occ", ylab = "accuracy",
xlim = c(0, max(g1000d_nndko, g1000d_bfko)),
main = "1000D acc vs NND k-occ"
)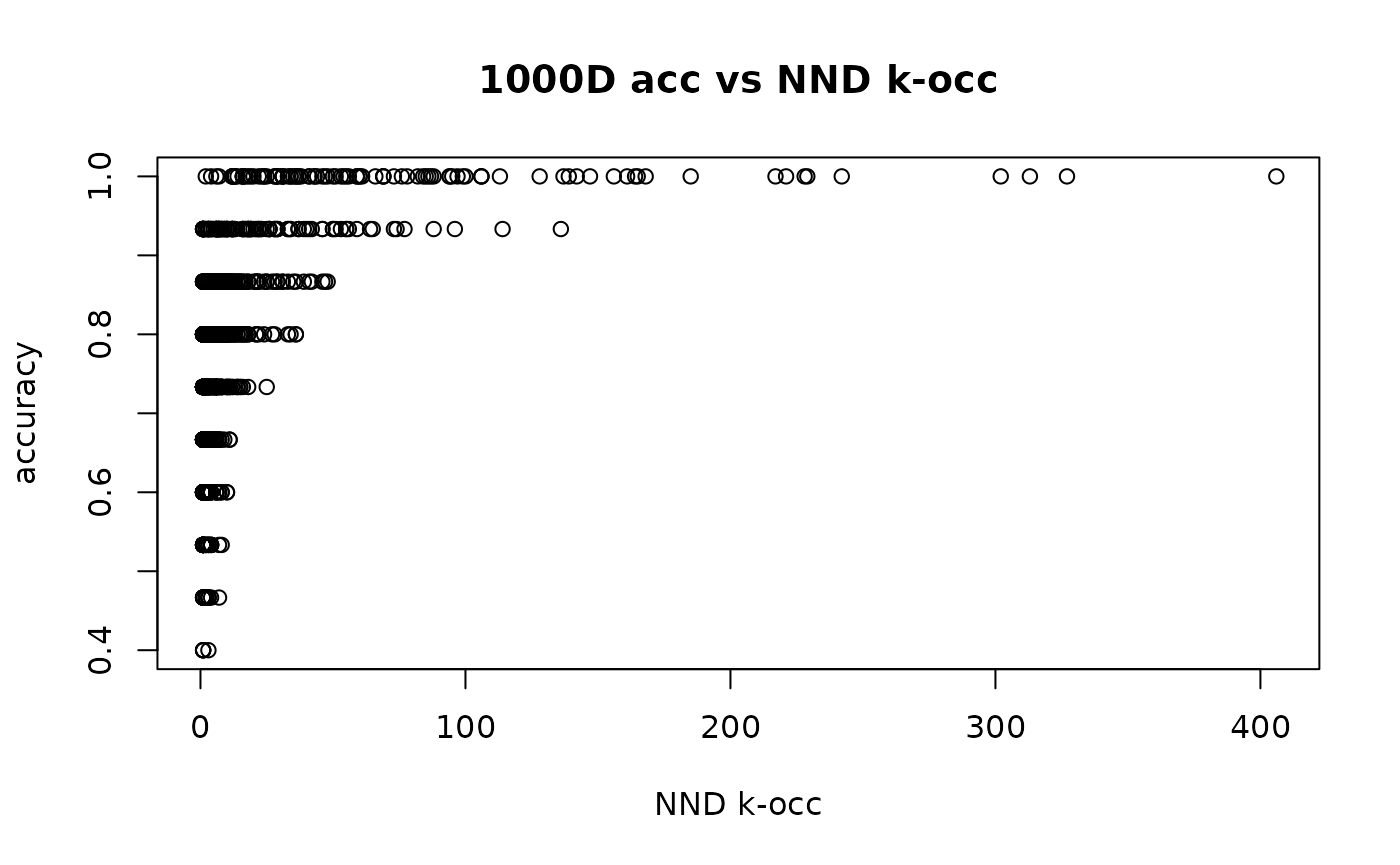
So the answer to the question is “not really”, but there is a trend. The empty space in the lower right of the plot indicates that items with a large k-occurrence (hubs) are very well predicted. And above a k-occurrence of 150, we are guaranteed to perfectly predict the neighborhood of an item. However, at the other end of the k-occurrence spectrum, we can see that while the lower bound on the predicted accuracy does plummet as the k-occurrence is reduced, some anti-hubs actually do have their neighborhoods very accurately predicted too.
Unfortunately this means that k-occurrence is a bit too rough to use to predict poorly-predicted items. Let’s say that we wanted to get all the items where the neighborhood was less than 90% accurate:
sum(g1000d_nnd_acc < 0.9)
#> [1] 767That’s already quite a lot of items: about three-quarters of the entire dataset. What is the largest k-occurrence for an item in the dataset with that accuracy threshold?
max(g1000d_nndko[g1000d_nnd_acc < 0.9])
#> [1] 48Then, to guarantee that we had found all the items that might be poorly predicted, we would need to filter out every item that had a k-occurrence smaller than that value, even though we know that some of them are well-predicted:
That’s most of the dataset. If we dropped the threshold to 80 accuracy, does it help?
A bit, but it’s still a substantial majority of the dataset. So whatever we decided to do with these items we wouldn’t be saving a huge amount of effort.
So much for that idea. What this suggests is not that we can’t improve results here, just that the effort of identifying individual points to filter out, treat differently and then merge back into the final neighbor graph means that just reprocessing the entire dataset in a different way is likely to be a competitive solution.
Detecting Problems Early
Back to looking at the k-occurrence distribution as a whole: we can see that the converged NND results, despite not being 100% accurate do a good job at expressing the hubness of the underlying data. How converged do the results need to be? What if we think of NND as a tool for identifying hubness in datasets as a whole rather than for accurate approximate nearest neighbor graphs? Could a much less unconverged NND graph, while obviously being even less accurate, still correctly identify a dataset as having hubs?
To test this, let’s run the NND method for only one iteration and get the k-occurrences that result:
g1000d_nnd_iter1 <- nnd_knn(g1000d, k = 15, metric = "euclidean", n_iters = 1)
g1000d_nndkoi1 <- k_occur(g1000d_nnd_iter1$idx, k = 15)How accurate are these results?
neighbor_overlap(g1000d_nnbf, g1000d_nnd_iter1, k = 15)
#> [1] 0.3202Ok, I think we can all agree we do not have an accurate neighbor graph. But let’s take a look at the k-occurrence distribution:
hist(g1000d_nndkoi1, main = "1000D 15-NND (1 iter)", xlab = "k-occurrences")
Looking familiar. Zooming in…
hist(pmin(g1000d_nndkoi1, max(g2d_bfko)),
main = "1000D 15-NND (1 iter, zoomed)",
xlab = "k-occurrences"
)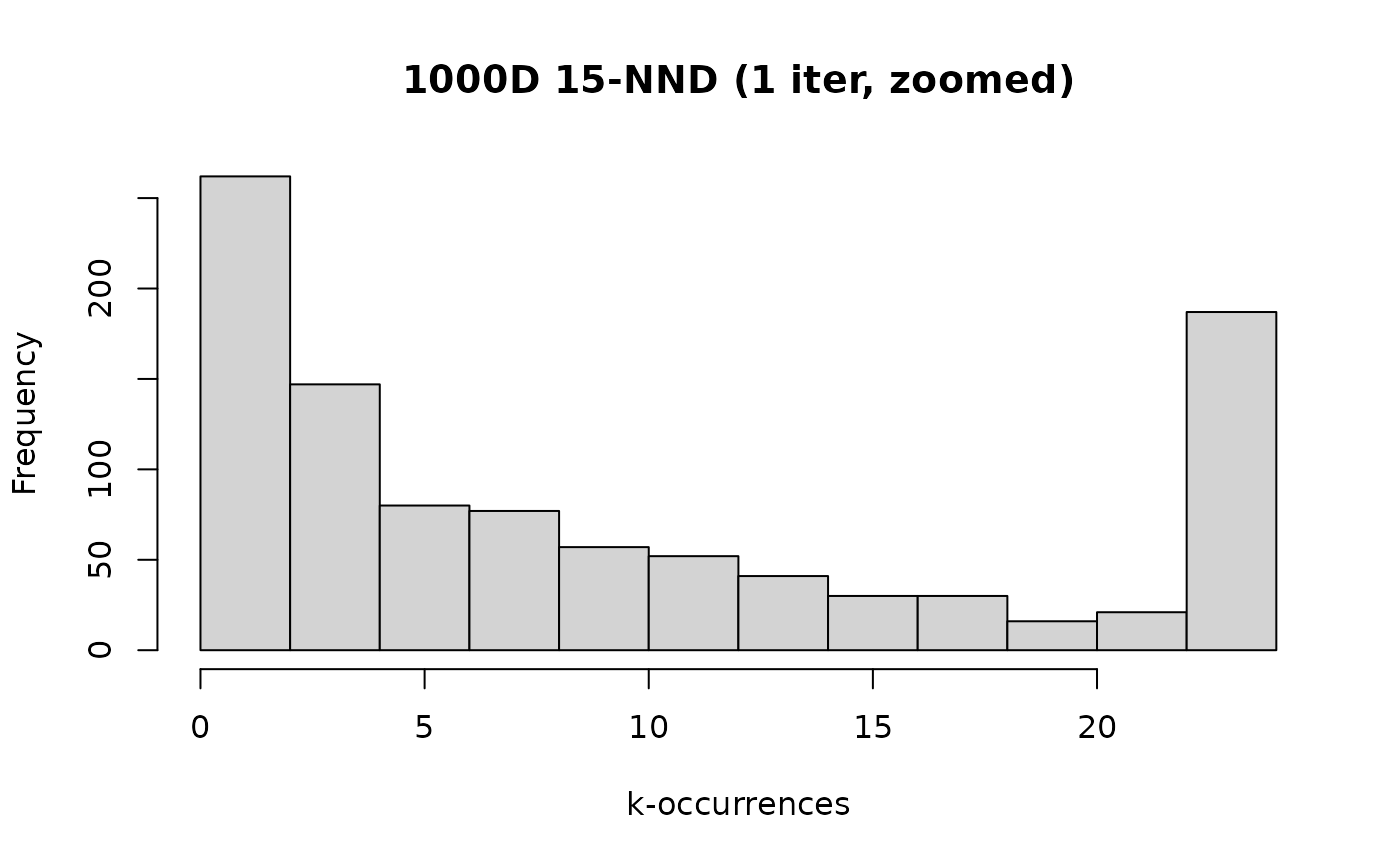
The distribution is at least similar to the converged version. Taking a look at some numbers:
summary(g1000d_nndkoi1)
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 1 2 7 15 17 212
sum(g1000d_nndkoi1 == 1)
#> [1] 163Compared to the converged (or exact) distribution, the median k-occurrence is not as low, the object with the largest k-occurrence, while large (, which seems like a good threshold to be concerned about the presence of hubs) is not as large, and there are fewer objects which are anti-hubs.
At least for this dataset, hubness can be qualitatively detected with even a very inaccurate neighbor graph. What about datasets that don’t contain hubs? Let’s just check that what we are seeing is not an artifact of unconverged nearest neighbor descent, by running through the same procedure with the 2D dataset:
g2d_nnd_iter1 <- nnd_knn(g2d, k = 15, metric = "euclidean", n_iters = 1)
g2d_nndkoi1 <- k_occur(g2d_nnd_iter1$idx, k = 15)
hist(g2d_nndkoi1, main = "2D 15-NND (1 iter)", xlab = "k-occurrences")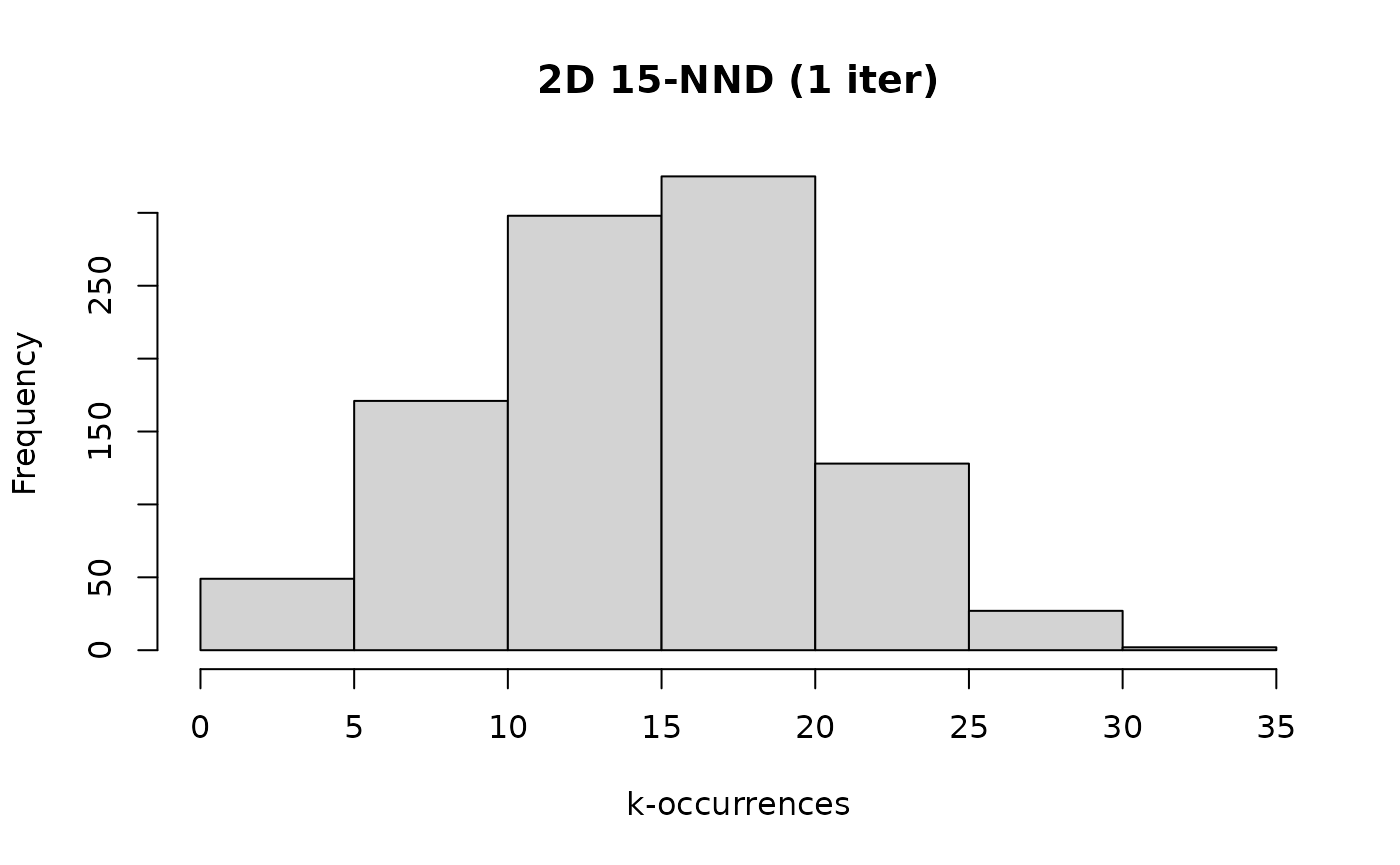
summary(g2d_nndkoi1)
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 1 11 15 15 19 33
sum(g2d_nndkoi1 == 1)
#> [1] 4
neighbor_overlap(g2d_nnbf, g2d_nnd_iter1, k = 15)
#> [1] 0.3496667We can see that the neighbor graph is also not very accurate after 1 iteration in the 2D case, but the distribution of k-occurrences also qualitatively resembles the exact result. This time, compared to the exact results there are slightly more anti-hubs and the maximum k-occurrence is increased, so the trends are slightly reversed compared to the 1000D data.
For at least qualitative identification of hubness, then, one iteration of nearest neighbor descent might be enough.
Improving accuracy
We know that nearest neighbor descent (at least with typical settings) may not give highly accurate results in high dimensions. And with the help of k-occurrences, we can even detect that it might be happening. But what can we do about it?
Weight candidates by degree
When creating the local join list for each object, we only have space
for max_candidates candidates. If there’s more than that,
then the candidates are randomly chosen. But with a uniform random
weighting, low-degree items could get crowded out of over-subscribed
candidate lists, but don’t get an opportunity to appear in many other
lists. Hub items, on the other hand, are going to appear on multiple
candidate lists, so even if they get crowded out of a few lists, they
are still going to be involved in the local join.
So what if, instead of weighting the candidates randomly but
uniformly, we weight the random selection by the degree of the
candidate? A hub with a large degree will tend to have a larger weight,
and due to how rnndescent’s internal heap implementation
works, will make it more likely to be evicted from the heap. Conversely,
a low-degree item will tend to have a lower weight.
This should give a more equitable distribution of candidates.
However, there is a small cost to doing this. At each iteration, we need
to calculate and store the k-occurrence of each item in the current
state of the graph. Honestly, this isn’t a huge amount of work, but as a
result weight_by_degree = FALSE by default. For the
high-dimensional case, it’s worth trying though:
g1000d_nnd_w <-
nnd_knn(g1000d,
k = 15,
metric = "euclidean",
weight_by_degree = TRUE
)
neighbor_overlap(g1000d_nnbf, g1000d_nnd_w)
#> [1] 0.8021333Like a 2%ish improvement. It’s not nothing. And despite the extra
computation and
storage required to calculate the k-occurrences in each iteration, with
high-dimensional data the distance calculations tend to dominate the run
time, so there’s no reason to not set
weight_by_degree = TRUE in this case. However, for the rest
of the vignette, we’ll keep it set to FALSE (the default)
so it’s easier to evaluate the contribution of other changes.
Use More Neighbors
One simple (slightly expensive) way is to keep more neighbors in the
calculation. For example, double the number of neighbors to
30, then get the top-15 accuracy:
g1000d_nnd_k30 <- nnd_knn(g1000d, k = 30, metric = "euclidean")
neighbor_overlap(g1000d_nnbf, g1000d_nnd_k30, k = 15)
#> [1] 0.9750667That’s a big improvement, but increasing k in this way
can be quite expensive in terms of run time.
Use More Candidates
Another way to improve accuracy is to increase the number of
candidates that are considered at each iteration. This is controlled by
the max_candidates parameter. Let’s try increasing that to
30:
g1000d_nnd_mc30 <- nnd_knn(g1000d, k = 15, metric = "euclidean", max_candidates = 30)
neighbor_overlap(g1000d_nnbf, g1000d_nnd_mc30)
#> [1] 0.8796Not as good as increasing k, but also not as
time-consuming and still an improvement over the default setting (which
is set to be the same as k). This should probably be your
first choice for improving accuracy.
Decrease the convergence tolerance
You could set delta to lower than the default of
0.001 or even to 0 to force the algorithm to
run until convergence:
g1000d_nnd_tol0 <- nnd_knn(g1000d, k = 15, metric = "euclidean", delta = 0)
neighbor_overlap(g1000d_nnbf, g1000d_nnd_tol0)
#> [1] 0.7909333But as you can see, it’s unlikely to achieve very much. The default parameters do a pretty good job of balancing accuracy and speed.
Merging Multiple Independent Results
What about taking advantage of the stochastic nature of the algorithm? If the results are sufficiently diverse between runs of NND, then we could generate two graphs from two separate runs, and then merge the results.
Let’s repeat NND and see what the accuracy of this new result is like.
g1000d_nnd_rep <- nnd_knn(g1000d, k = 15, metric = "euclidean")
neighbor_overlap(g1000d_nnbf, g1000d_nnd_rep, k = 15)
#> [1] 0.7858That’s similar to the first run. That’s re-assuring in the sense that the variance of the accuracy doesn’t seem to be that high between one run to the next. But hopefully that doesn’t also mean that NND is producing a very similar neighbor graph each time, in which case merging them won’t be very helpful. Time to find out:
g1000d_nnd_merge <- merge_knn(list(g1000d_nnd, g1000d_nnd_rep))
neighbor_overlap(g1000d_nnbf, g1000d_nnd_merge, k = 15)
#> [1] 0.9056667That’s a big improvement. So it does seem like there is some diversity in the results.
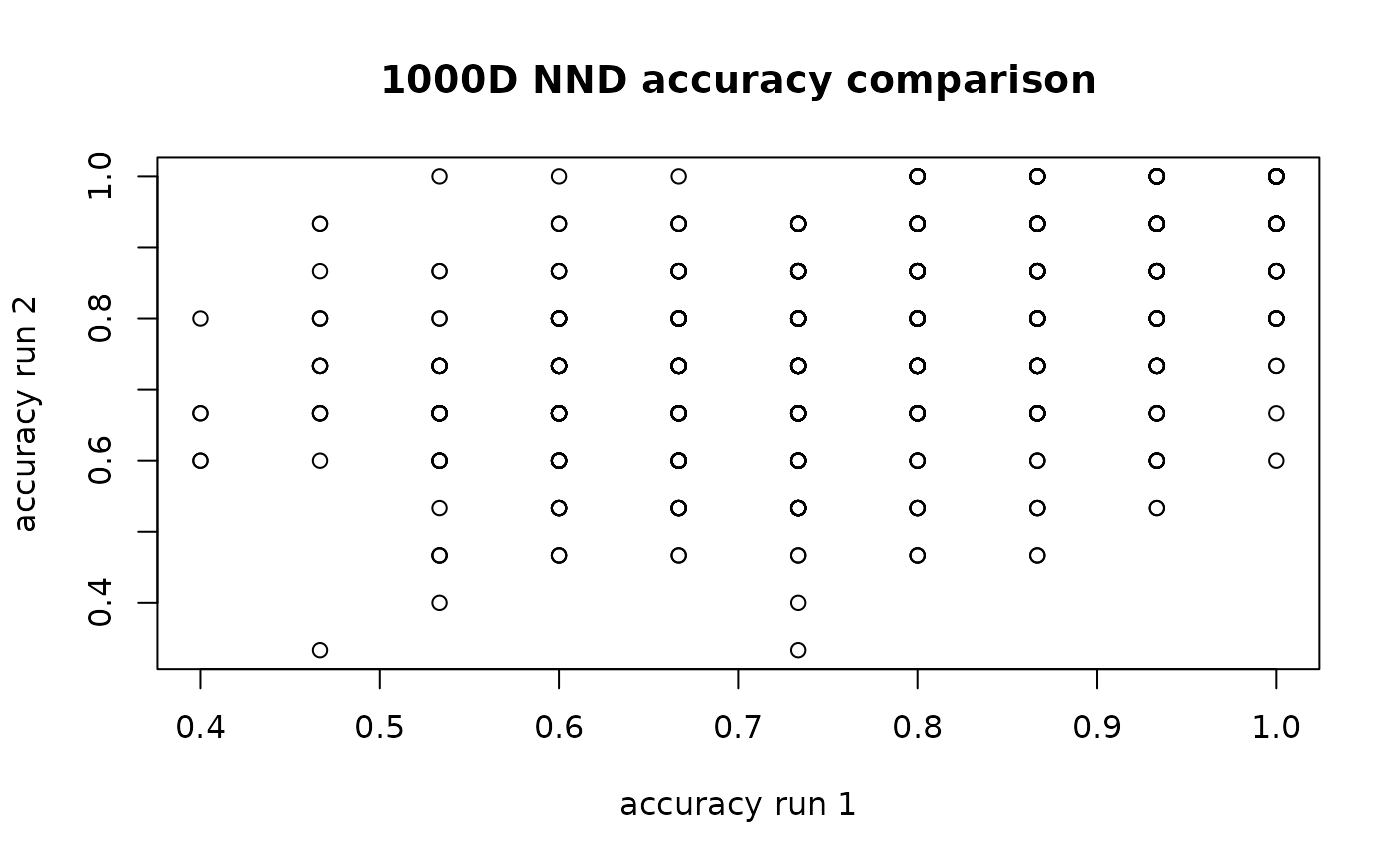
g1000d_nnd_rep_acc <-
neighbor_overlap(g1000d_nnbf, g1000d_nnd_rep, k = 15, ret_vec = TRUE)$overlaps
plot(
g1000d_nnd_acc,
g1000d_nnd_rep_acc,
main = "1000D NND accuracy comparison",
xlab = "accuracy run 1",
ylab = "accuracy run 2"
)
cor(g1000d_nnd_acc, g1000d_nnd_rep_acc)
#> [1] 0.5069483Despite the similar overall accuracies, there’s quite a large variance between runs in terms of which items have accurate neighborhoods.
So there might be some scope for improving the results by merging different runs, especially if you can run the individual NND routines in parallel.
Using a Search Graph
Practically, the simplest way to improve results with
rnndescent is to convert the neighbor graph into a search
graph, and then query it with the original data.
First, the preparation step:
g1000d_search_graph <-
prepare_search_graph(
data = g1000d,
graph = g1000d_nnd,
metric = "euclidean",
diversify_prob = 1,
pruning_degree_multiplier = 1.5
)This augments the neighbor graph with the reversed edges of the neighbor graph, so that if is one of the nearest neighbors of , we guarantee that is also considered a near neighbor . This ameliorates the issue of anti-hubs because all neighbors of an anti-hub now have it in their neighbor list.
The downside of including all reversed edges in the neighbor graph is
that the neighbor list of a hub is now going to be very large as it
consists of the
nearest neighbors of the hub and then all the items that consider the
hub a near neighbor, which by definition is a lot. This can make the
search graph inefficient, as a disproportionate amount of time will be
spent searching neighbors of the hub. The diversify_prob
and pruning_degree_multiplier parameters are used to reduce
back down the out-degree of each node (the number of out-going edges).
This results in objects with a varying number of neighbors, in this case
to a maximum of 22. This is about 50% larger than k = 15 to
account for the introduction of the reverse edges. Anti-hubs can be
reintroduced due to the edge reduction, but hopefully the distribution
of edges is a bit more equitable.
Here is a summary and histogram of the k-occurrences of the search graph:
g1000d_sgko <- k_occur(g1000d_search_graph)
hist(g1000d_sgko, main = "search graph k-occurrences", xlab = "k-occurrences")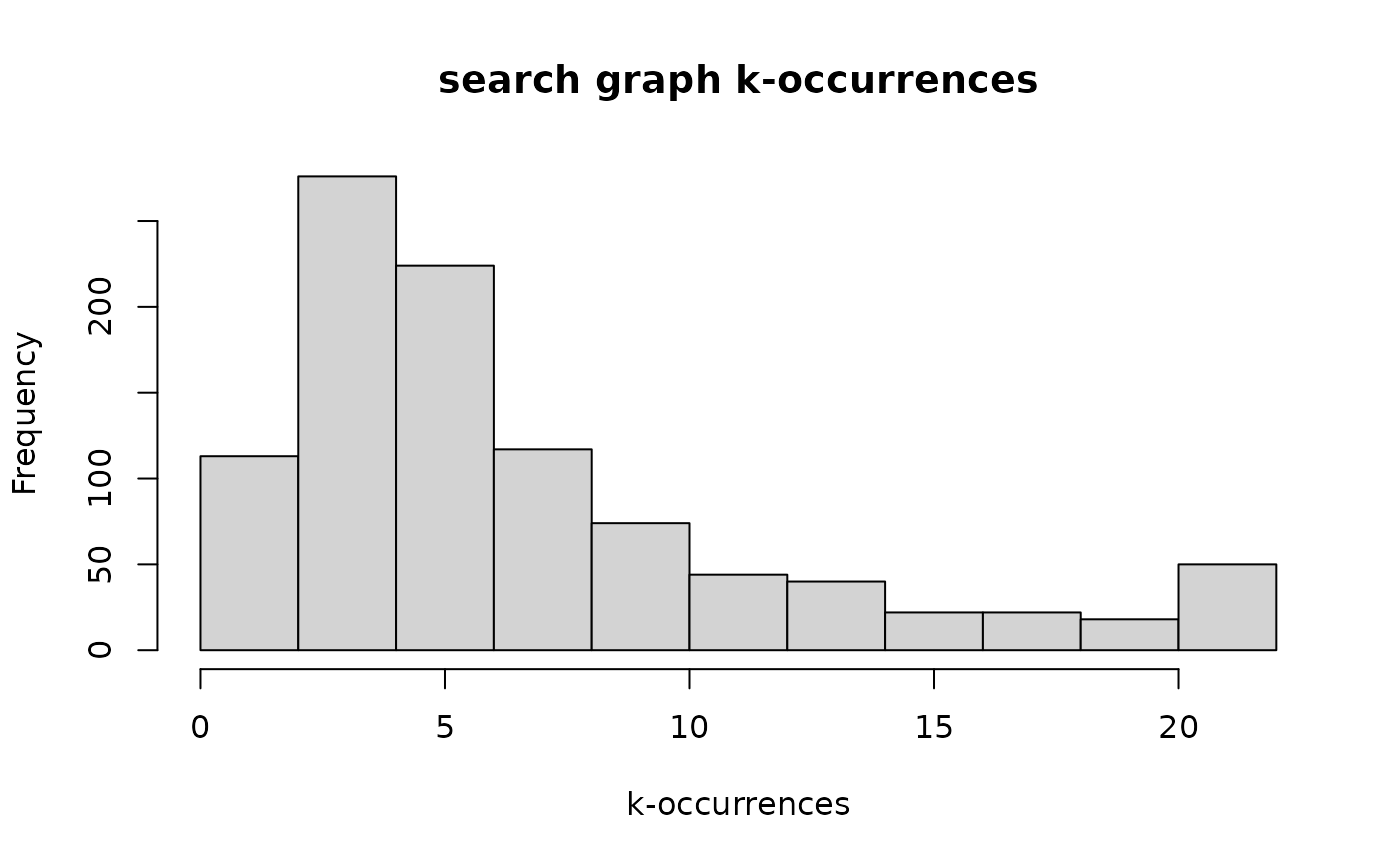
summary(g1000d_sgko)
#> Min. 1st Qu. Median Mean 3rd Qu. Max.
#> 1.000 4.000 5.000 7.258 9.000 22.000
sum(g1000d_sgko == 1)
#> [1] 24This is not quite as skewed as the neighbor graph, but there is still a lot of room for improvement.
At any rate, with the search graph in hand, we can now search it using our original data as a query:
g1000d_search <-
graph_knn_query(
query = g1000d,
reference = g1000d,
reference_graph = g1000d_search_graph,
k = 15,
metric = "euclidean",
init = g1000d_nnd,
epsilon = 0.1
)Are the results improved?
neighbor_overlap(g1000d_nnbf, g1000d_search, k = 15)
#> [1] 0.9979333Yes, the accuracy is now nearly perfect. The disadvantages of the
search graph approach for building a neighbor graph is that it is less
efficient than NND: graph_knn_query must assume that the
query data is entirely different to the
reference data. The advantage is that we can make use of
reverse edges and, more importantly, back-tracking (controlled via the
epsilon parameter), which seems to make the difference in
this example.
The procedure above is the recommended practice of using
graph_knn_query with a search graph generated from the
neighbor graph. You are not required to use a search graph as the
argument to the reference_graph parameter. Here is the
back-tracking search using the neighbor graph directly and everything
else the same:
g1000d_nnd_search <-
graph_knn_query(
query = g1000d,
reference = g1000d,
reference_graph = g1000d_nnd,
k = 15,
metric = "euclidean",
init = g1000d_nnd,
epsilon = 0.1
)
neighbor_overlap(g1000d_nnbf, g1000d_nnd_search, k = 15)
#> [1] 0.9845333Accuracies are nearly as good. You can save even more time by turning
off back-tracking (epsilon = 0):
g1000d_nnd_search0 <-
graph_knn_query(
query = g1000d,
reference = g1000d,
reference_graph = g1000d_nnd,
k = 15,
metric = "euclidean",
init = g1000d_nnd,
epsilon = 0
)
neighbor_overlap(g1000d_nnbf, g1000d_nnd_search0, k = 15)
#> [1] 0.8286667but accuracies are now noticeably less improved. Using the search graph without back-tracking gives slightly better accuracies:
g1000d_search0 <-
graph_knn_query(
query = g1000d,
reference = g1000d,
reference_graph = g1000d_search_graph,
k = 15,
metric = "euclidean",
init = g1000d_nnd,
epsilon = 0
)
neighbor_overlap(g1000d_nnbf, g1000d_search0, k = 15)
#> [1] 0.8489333but it seems like some sort of back-tracking is to be recommended
with this approach. The downside is that you could be searching through
a large proportion of the dataset, in which case you would save time by
using the brute_force_query.
In conjunction with epsilon, you can also use
max_search_fraction which will terminate the search if the
fraction of the dataset searched exceeds the specified value. Set it to
a value between 0 and 1, e.g. max_search_fraction = 0.1 if
you don’t want more than 10% of the reference data being searched. The
default is 1, so that epsilon entirely
controls the search termination. A similar parameter is used in (Harwood and Drummond 2016).
g1000d_nnd_search_max <-
graph_knn_query(
query = g1000d,
reference = g1000d,
reference_graph = g1000d_nnd,
k = 15,
metric = "euclidean",
init = g1000d_nnd,
epsilon = 0.1,
max_search_fraction = 0.1
)
neighbor_overlap(g1000d_nnbf, g1000d_nnd_search_max, k = 15)
#> [1] 0.8233333Accuracies are again reduced.
Conclusions
- High dimensional data leads to hubs.
- The “hubness” of an item in a dataset can be measured by the k-occurrence in the corresponding nearest neighbor graph. The higher the k-occurrence, the more of a hub it is.
- The existence of a hubs implies the existence of “anti-hubs”, i.e. items with a low k-occurrence. A small number of hubs can create a disproportionately larger number of anti-hubs, with a larger value of the k-occurrence creating more anti-hubs.
- The accuracy of nearest neighbor descent is reduced by the presence of hubs: specifically, the lower the k-occurrence of an item, the greater the probability of a low accuracy of its nearest neighbors.
- Accuracy of nearest neighbor descent can be improved by searching for a larger number of neighbors and then truncating the result to the desired size, at the cost of a longer run-time and memory usage.
- Alternatively, you can run the the nearest neighbor descent multiple times from different random starting points and merge the results.
- Setting
weight_by_degree = TRUEis probably worth doing, albeit it gives a very modest improvement. - More accurate and efficient results are obtained by converting the nearest neighbor descent results into a search graph and then querying the graph with the original data, using the nearest neighbor results for initialization and a back-tracking search.
If you are concerned with potential hubs interfering with the accuracy of the neighbor graph, I suggest the following steps:
- Generate a neighbor graph with
nnd_knnand default parameters, or even for just 1 iteration. - Evaluate the hubness of the graph with
k_occur. - If the maximum k-occurrence exceeds a threshold (maybe
10 * kis a good starting point), then you could try the following: - Restart
nnd_knn(you as may as well use the output from the first step as the initialization) withmax_candidatesset to a larger value. You probably don’t want to set it larger than60. - Repeat step 4 to get a second graph.
- Merge the graphs from steps 4 and 5 with
merge_knn. - Use the merged graph for
prepare_search_graph, and then rungraph_knn_querywith back-tracking search (setepsilon > 0) to refine the results further. 8 If in step 3, the maximum k-occurrence is less than the threshold, then you are probably ok to runnnd_knnwith defaults.
This should provide a robust approach to producing accurate approximate nearest neighbors without spending time on unnecessary graph search when the results are probably already quite good.
For more on the effect of hubness and nearest neighbors, and more advanced attempts to fix the problem, see the work of Flexer and co-workers (Schnitzer et al. 2012; Flexer 2016; Feldbauer and Flexer 2019; Feldbauer et al. 2019) and Radovanović and co-workers (Radovanovic et al. 2010; Bratić et al. 2019).